
PythonでTesseractを使ってみる
はじめに
皆さんこんにちは。ファブテラスいわてスタッフの鈴木です。
今回の内容はタイトルにもある通り、PythonでTesseractを使ってみるというものです。
私は以前、tesseractに少し触れる機会がありそこで興味をひかれたのですが、気づいたらその時以来全く使っていませんでした。なので、今回は復習を兼ねて、pythonでtesseractを使ってみたいと思います。
今回はものづくり系の記事ではないのですが、最後まで読んでくだされば幸いです。
Tesseractとは
・オープンソースのOCRエンジン
・画像の中にある文字を読み取り出力する
今回の動作環境
・macOS Monterey バージョン12.1
・Python 3.9.5
・Tesseract 4.1.3
・pyocr 0.8.1
Tesseractの導入
まずはターミナルから、brewでTesseractをインストールします
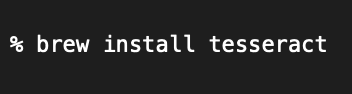
次のコマンドを入力すると、文字認識可能な言語を確認できます
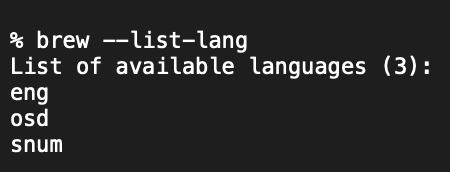
このままでは日本語が入っていないので、日本語の学習モデルのファイルをhttps://github.com/tesseract-ocr/tessdata/blob/main/jpn.traineddataからダウンロードします。
jpn.traineddataという名前のファイルをダウンロードできたかと思います。
次にtesseract関連のパスを以下のコマンドで表示させ、学習済みモデルの入ったディレクトリを探します。
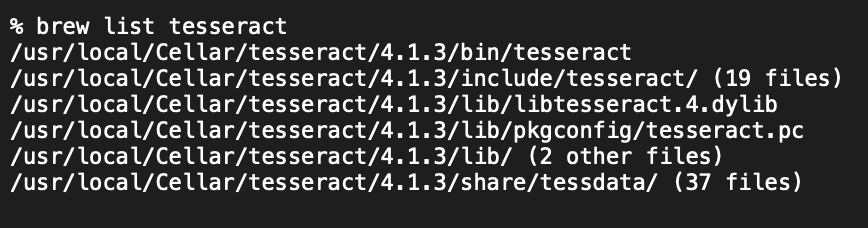
この中だとtessdataに入っているようです

中を見ると拡張子がtraineddataとなっているファイルがあると思いますが、これが学習データらしいです。ここで、先ほどダウンロードしたjpn.traineddataをtessdataに入れます。
ここでもう一度対応言語を確認すると….
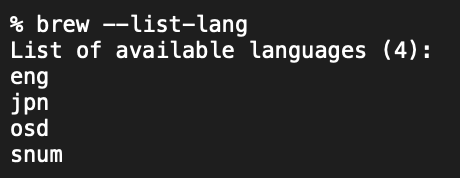
jpnが追加されているのが分かります。
さっそくPythonでTesseractをやってみた
今回は、以下のファブテラスいわてのHPのスクリーンショット、”test_img.jpg”を使います。

以下のコードを実行します。
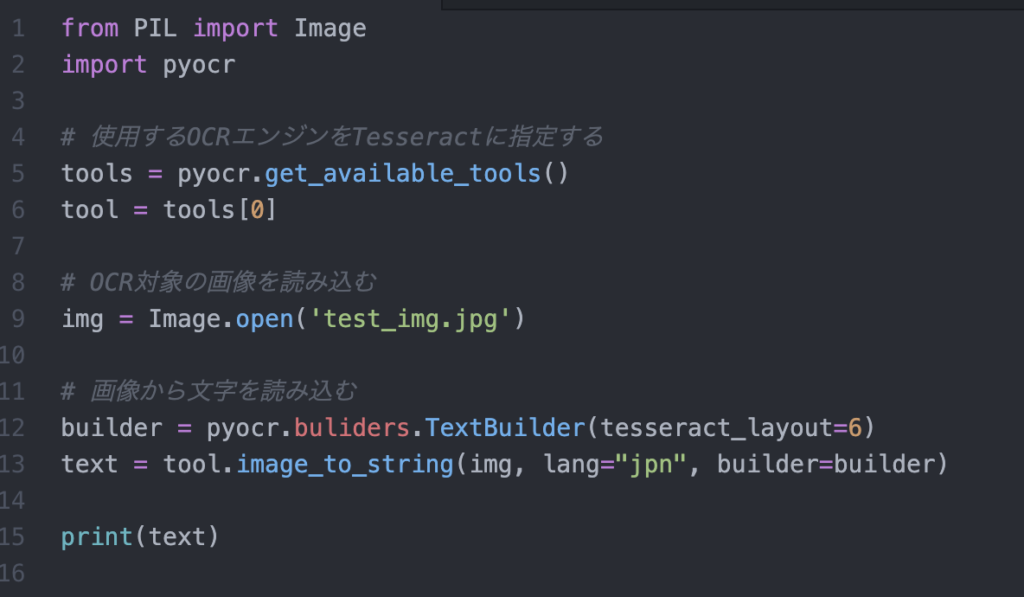
以下が実行結果です

3Dプリンターの3が③になってしまっていますね……それとカッコも1つ正確に読み取れていないようです。
ですが、ほぼ正確に画像の文字をテキストとして認識してくれていますね。
おわりに
これはあとから知ったことなのですが、ubuntuのサイトhttps://packages.ubuntu.com/focal/tesseract-ocr-jpnの学習データの方が高い精度で認識できるようです。
なので、Tesseractを日本語で使ってみる際はそちらの学習データを使うことをおすすめします。
最後にここまで読んでくださりありがとうございました。

